%22%3E%3Cpath%20fill%3D%22%23067DE5%22%20d%3D%22M5.766%203.208c.126-.356.33-.68.598-.948a2.344%202.344%200%200%201%203.686.547c.564%201.028%201.162%202.03%201.744%203.048.971%201.688%201.953%203.376%202.913%205.068a2.333%202.333%200%200%201-4.08%202.263l-2.56-4.448a.5.5%200%200%200-.062-.088.9.9%200%200%201-.186-.28C7.44%207.706%207.05%207.05%206.67%206.386c-.243-.43-.497-.853-.74-1.282a2.34%202.34%200%200%201-.31-1.242%201.7%201.7%200%200%201%20.146-.655%22%2F%3E%3Cpath%20fill%3D%22%23FABC04%22%20d%3D%22M5.766%203.209q-.084.304-.107.618c-.016.464.102.924.34%201.323q.93%201.6%201.853%203.211c.056.096.101.192.158.28-.339.587-.677%201.169-1.021%201.756A370%20370%200%200%201%205.56%2012.86c-.023%200-.028-.011-.034-.028a.4.4%200%200%201%20.023-.13%202.27%202.27%200%200%200-.542-2.24%202.15%202.15%200%200%200-1.323-.683%202.3%202.3%200%200%200-1.813.502%202%202%200%200%201-.27.238.04.04%200%200%201-.04-.028c.27-.47.535-.937.806-1.405l3.354-5.82c.01-.022.028-.04.04-.06%22%2F%3E%3Cpath%20fill%3D%22%2334A852%22%20d%3D%22M1.584%2010.51c.107-.096.21-.197.321-.287a2.333%202.333%200%200%201%203.731%201.417c.07.402.041.814-.086%201.202a1%201%200%200%201-.023.096c-.051.088-.096.186-.153.276a2.27%202.27%200%200%201-2.213%201.18%202.32%202.32%200%200%201-2.138-2.02%202.26%202.26%200%200%201%20.31-1.504c.057-.101.125-.192.187-.294.028-.023.016-.07.07-.07%22%2F%3E%3Cpath%20fill%3D%22%23FABC04%22%20d%3D%22M1.584%2010.51c-.023.023-.023.062-.062.07-.005-.04.017-.061.04-.088l.023.023%22%2F%3E%3Cpath%20fill%3D%22%23E1C025%22%20d%3D%22M5.524%2012.938c-.023-.04%200-.07.023-.096l.023.024-.044.07%22%2F%3E%3C%2Fg%3E%3Cdefs%3E%3CclipPath%20id%3D%220dcc9_a%22%3E%3Cpath%20fill%3D%22%23fff%22%20d%3D%22M1%201h14v14H1z%22%2F%3E%3C%2FclipPath%3E%3C%2Fdefs%3E%3C%2Fsvg%3E)






%22%20d%3D%22M7.997%201.992c-2.507%200-3.243%200-3.383.014a3%203%200%200%200-1.181.3%202.4%202.4%200%200%200-.69.504%202.57%202.57%200%200%200-.696%201.464c-.067.587-.085%201.18-.056%201.77v1.953c0%202.506%200%203.238.015%203.38.018.401.114.795.286%201.158a2.53%202.53%200%200%200%201.64%201.34q.429.102.871.115c.15.006%201.665.01%203.183.01%201.519%200%203.034%200%203.18-.008q.456-.01.9-.12a2.52%202.52%200%200%200%201.64-1.343c.169-.356.265-.743.283-1.138.008-.103.011-1.753.011-3.4s-.004-3.294-.012-3.398a2.9%202.9%200%200%200-.285-1.146%202.4%202.4%200%200%200-.514-.705%202.6%202.6%200%200%200-1.463-.694%2011%2011%200%200%200-1.772-.056z%22%2F%3E%3Cpath%20fill%3D%22url(%23de42a_b)%22%20d%3D%22M7.997%201.992c-2.507%200-3.243%200-3.383.014a3%203%200%200%200-1.181.3%202.4%202.4%200%200%200-.69.504%202.57%202.57%200%200%200-.696%201.464c-.067.587-.085%201.18-.056%201.77v1.953c0%202.506%200%203.238.015%203.38.018.401.114.795.286%201.158a2.53%202.53%200%200%200%201.64%201.34q.429.102.871.115c.15.006%201.665.01%203.183.01%201.519%200%203.034%200%203.18-.008q.456-.01.9-.12a2.52%202.52%200%200%200%201.64-1.343c.169-.356.265-.743.283-1.138.008-.103.011-1.753.011-3.4s-.004-3.294-.012-3.398a2.9%202.9%200%200%200-.285-1.146%202.4%202.4%200%200%200-.514-.705%202.6%202.6%200%200%200-1.463-.694%2011%2011%200%200%200-1.772-.056z%22%2F%3E%3Cpath%20fill%3D%22%23fff%22%20d%3D%22M7.997%203.564c-1.204%200-1.355.005-1.828.027a3.3%203.3%200%200%200-1.076.206%202.27%202.27%200%200%200-1.3%201.296c-.13.344-.199.708-.206%201.076-.02.473-.025.627-.025%201.828s.005%201.355.027%201.829c.007.367.076.731.204%201.076a2.27%202.27%200%200%200%201.298%201.3c.345.128.709.198%201.076.205.474.022.624.027%201.828.027s1.355-.005%201.829-.027a3.3%203.3%200%200%200%201.076-.206%202.27%202.27%200%200%200%201.297-1.297c.129-.344.198-.708.206-1.076.021-.473.027-.624.027-1.828s-.005-1.356-.027-1.828a3.3%203.3%200%200%200-.206-1.077A2.27%202.27%200%200%200%2010.9%203.8a3.3%203.3%200%200%200-1.078-.206c-.472-.024-.624-.03-1.825-.03m-.398.799h.398c1.184%200%201.322.004%201.792.025.281.003.56.055.823.152a1.47%201.47%200%200%201%20.841.841c.098.264.15.542.153.824.02.467.025.607.025%201.791s-.004%201.321-.025%201.792c-.004.28-.055.56-.153.823a1.47%201.47%200%200%201-.84.84%202.4%202.4%200%200%201-.824.153c-.467.022-.608.026-1.792.026-1.183%200-1.324-.005-1.791-.026a2.5%202.5%200%200%201-.824-.153%201.47%201.47%200%200%201-.84-.84%202.5%202.5%200%200%201-.153-.824c-.023-.468-.028-.607-.028-1.79%200-1.182.005-1.32.026-1.791.003-.281.055-.56.152-.824a1.47%201.47%200%200%201%20.841-.84%202.5%202.5%200%200%201%20.823-.154%2025%2025%200%200%201%201.394-.025zm2.762.736a.532.532%200%201%200%200%201.064.532.532%200%200%200%200-1.064m-2.364.622a2.277%202.277%200%201%200%200%204.553%202.277%202.277%200%200%200%200-4.553m0%20.799a1.478%201.478%200%201%201%200%202.956%201.478%201.478%200%200%201%200-2.956%22%2F%3E%3Cdefs%3E%3CradialGradient%20id%3D%22de42a_a%22%20cx%3D%220%22%20cy%3D%220%22%20r%3D%221%22%20gradientTransform%3D%22matrix(0%20-11.9011%2011.0725%200%205.2%2014.933)%22%20gradientUnits%3D%22userSpaceOnUse%22%3E%3Cstop%20stop-color%3D%22%23FD5%22%2F%3E%3Cstop%20offset%3D%22.1%22%20stop-color%3D%22%23FD5%22%2F%3E%3Cstop%20offset%3D%22.5%22%20stop-color%3D%22%23FF543E%22%2F%3E%3Cstop%20offset%3D%221%22%20stop-color%3D%22%23C837AB%22%2F%3E%3C%2FradialGradient%3E%3CradialGradient%20id%3D%22de42a_b%22%20cx%3D%220%22%20cy%3D%220%22%20r%3D%221%22%20gradientTransform%3D%22matrix(1.04484%205.218%20-21.50815%204.30673%20.009%202.925)%22%20gradientUnits%3D%22userSpaceOnUse%22%3E%3Cstop%20stop-color%3D%22%233771C8%22%2F%3E%3Cstop%20offset%3D%22.128%22%20stop-color%3D%22%233771C8%22%2F%3E%3Cstop%20offset%3D%221%22%20stop-color%3D%22%2360F%22%20stop-opacity%3D%220%22%2F%3E%3C%2FradialGradient%3E%3C%2Fdefs%3E%3C%2Fsvg%3E)



%22%3E%3Cpath%20fill%3D%22%233E63DD%22%20d%3D%22M7.073%205.163c0-.6.498-.831%201.304-.831a8.6%208.6%200%200%201%203.823.989V1.703A10.1%2010.1%200%200%200%208.377%201c-3.106%200-5.19%201.627-5.19%204.344%200%204.251%205.838%203.56%205.838%205.393%200%20.717-.613.939-1.475.939-1.27%200-2.912-.526-4.2-1.226v3.665c1.326.577%202.755.878%204.2.885%203.193%200%205.394-1.577%205.394-4.341%200-4.588-5.872-3.77-5.872-5.496%22%2F%3E%3C%2Fg%3E%3Cdefs%3E%3CclipPath%20id%3D%226e28b_a%22%3E%3Cpath%20fill%3D%22%23fff%22%20d%3D%22M1%201h14v14H1z%22%2F%3E%3C%2FclipPath%3E%3C%2Fdefs%3E%3C%2Fsvg%3E)
%22%3E%3Cpath%20d%3D%22M4.004%202h7.99A2.005%202.005%200%200%201%2014%204.003v7.99A2.005%202.005%200%200%201%2011.994%2014h-7.99A2.006%202.006%200%200%201%202%2011.995V4.008A2.004%202.004%200%200%201%204.002%202zm7.183%209.818a.634.634%200%200%200%20.633-.632v-6.37a.634.634%200%200%200-.633-.632H4.815a.63.63%200%200%200-.632.632v6.37a.63.63%200%200%200%20.632.632z%22%2F%3E%3Cpath%20d%3D%22M6.726%209.628a.36.36%200%200%201-.36-.36V6.723a.36.36%200%200%201%20.36-.365h2.55a.36.36%200%200%201%20.36.36v2.546a.365.365%200%200%201-.36.364z%22%2F%3E%3C%2Fg%3E%3Cdefs%3E%3CclipPath%20id%3D%2284b16_a%22%3E%3Cpath%20fill%3D%22%23fff%22%20d%3D%22M2%202h12v12H2z%22%2F%3E%3C%2FclipPath%3E%3C%2Fdefs%3E%3C%2Fsvg%3E)
%22%3E%3Cpath%20d%3D%22M3.331%209.787c.038.006.093-.022.128-.116l.01-.03a1%201%200%200%201%20.09-.216.4.4%200%200%201%20.555-.117.394.394%200%200%201%20.147.473%201.1%201.1%200%200%200-.077.42c.025.299.207.418.37.432.16.005.271-.085.3-.15.017-.039.002-.063-.006-.073-.024-.032-.065-.022-.104-.013a.4.4%200%200%201-.093.013h-.005a.2.2%200%200%201-.165-.086c-.046-.07-.043-.175.006-.295l.024-.053c.08-.18.214-.482.064-.769a.68.68%200%200%200-.603-.384.66.66%200%200%200-.486.212l-.001.001c-.22.244-.255.576-.212.694.016.043.04.055.058.057m8.023-1.607c-.003.137.076.25.175.251.1.002.183-.108.185-.245s-.077-.25-.176-.252c-.1-.002-.183.108-.184.246m-.042-.564q.143-.02.288%200c.052-.12.06-.326.014-.55-.07-.333-.163-.535-.357-.503-.193.031-.2.273-.13.606.038.187.108.347.185.447%22%2F%3E%3Cpath%20d%3D%22M4.273%2011.882c.816%201.89%202.68%203.05%204.867%203.115%202.345.07%204.314-1.036%205.14-3.023.054-.14.283-.768.283-1.322%200-.558-.314-.789-.513-.789a10%2010%200%200%200-.1-.342l-.11-.297c.219-.329.222-.622.193-.788a1%201%200%200%200-.288-.562c-.171-.182-.523-.368-1.017-.506l-.26-.073c0-.01-.012-.614-.024-.873a3%203%200%200%200-.114-.767c-.107-.39-.294-.731-.529-.95.645-.671%201.048-1.412%201.047-2.047-.002-1.222-1.495-1.593-3.335-.826l-.39.166-.648-.639-.067-.065c-2.1-1.84-8.66%205.488-6.562%207.268l.459.39a2.2%202.2%200%200%200-.128%201.05c.05.489.301.956.708%201.318.386.344.895.563%201.388.562m6.882-6.579c.018-.003.064-.02.157-.015q.15.008.266.086c.309.207.353.708.369%201.075.01.21.034.717.043.863.02.332.107.379.283.437.098.033.191.058.327.096.41.116.652.233.806.384a.5.5%200%200%201%20.147.29c.049.355-.273.793-1.127%201.19-.934.436-2.065.546-2.846.459l-.274-.031c-.625-.085-.982.727-.607%201.284.242.358.901.592%201.56.592%201.512%200%202.673-.648%203.105-1.209l.035-.05c.021-.032.004-.05-.023-.031-.353.243-1.921%201.207-3.6.916%200%200-.203-.033-.389-.106-.147-.058-.457-.2-.494-.52%201.353.421%202.206.023%202.206.023a.04.04%200%200%200%20.025-.038v-.003a.04.04%200%200%200-.04-.035h-.004s-1.11.165-2.158-.221c.114-.373.418-.238.877-.201a6.4%206.4%200%200%200%202.127-.234c.473-.138%201.09-.406%201.572-.787.163.36.222.757.222.757s.125-.023.232.042c.099.062.172.19.122.522-.101.62-.364%201.124-.805%201.587-.27.293-.59.537-.948.717l-.019.009a4%204%200%200%201-.602.26l-.03.008c-1.661.545-3.362-.054-3.91-1.342a2%202%200%200%201-.107-.29l-.004-.014c-.233-.849-.035-1.867.586-2.508.038-.04.077-.09.077-.15%200-.05-.032-.103-.06-.14-.216-.317-.968-.856-.817-1.899.108-.75.761-1.277%201.368-1.245l.154.008c.264.016.493.05.71.06.364.015.69-.038%201.076-.362.13-.109.235-.204.412-.234m-1.63-1.885a.025.025%200%200%201%20.016.044%201.3%201.3%200%200%200-.24.24.023.023%200%200%200%20.018.037c.383.004.922.138%201.273.336.024.014.007.06-.02.054a5.15%205.15%200%200%200-2.304.006c-.807.198-1.422.503-1.872.831-.022.017-.049-.013-.031-.034.52-.605%201.16-1.13%201.734-1.424.02-.01.04.011.03.03a1.6%201.6%200%200%200-.161.396v.005q.002.021.023.023a.02.02%200%200%200%20.012-.004c.357-.244.978-.506%201.522-.54M2.04%208.065c-.405-.773.442-2.276%201.034-3.125%201.463-2.097%203.753-3.685%204.814-3.397.172.049.743.714.743.714s-1.06.59-2.043%201.415C5.263%204.697%204.263%206.187%203.663%207.804a1.8%201.8%200%200%200-1.14.73c-.15-.127-.433-.373-.483-.469m1.747.242a1.3%201.3%200%200%201%20.32-.024h-.003c.425.024%201.049.35%201.191%201.279.126.82-.075%201.658-.84%201.79v-.001q-.088.016-.19.016h-.03.002c-.708-.02-1.474-.66-1.55-1.421-.083-.84.344-1.486%201.1-1.64%22%2F%3E%3Cpath%20d%3D%22M9.155%207.463a.98.98%200%200%200-.577.19c-.093.068-.18.162-.168.22.005.018.018.032.05.037.078.008.344-.127.652-.146.217-.014.398.055.536.116.139.061.224.1.257.066q.032-.035-.017-.119a.8.8%200%200%200-.36-.29%201%201%200%200%200-.373-.074m1.595%201.163c.122.06.257.037.3-.053.045-.09-.02-.212-.142-.272s-.257-.037-.3.053c-.045.09.02.212.142.272M9.37%208.04a.66.66%200%200%200-.344.143c-.054.048-.088.101-.088.138l.014.034.03.011c.04%200%20.132-.037.132-.037a1.1%201.1%200%200%201%20.588-.06h-.006c.09.01.134.016.153-.015.006-.009.013-.029-.005-.059-.042-.068-.224-.184-.473-.155%22%2F%3E%3Cpath%20d%3D%22m8.576%207.654.003-.001v-.001zm-6.399%202.354v-.007l-.001-.003zm9.783.289-.034.007-.01.004z%22%2F%3E%3C%2Fg%3E%3Cdefs%3E%3CclipPath%20id%3D%229c0a0_a%22%3E%3Cpath%20fill%3D%22%23fff%22%20d%3D%22M1%201h14v14H1z%22%2F%3E%3C%2FclipPath%3E%3C%2Fdefs%3E%3C%2Fsvg%3E)
%22%3E%3Cpath%20fill%3D%22%230080F1%22%20d%3D%22M13.264%201.07H2.75A1.734%201.734%200%200%200%201%202.791v10.41a1.74%201.74%200%200%200%201.75%201.729h10.5A1.736%201.736%200%200%200%2015%2013.209v-10.4a1.73%201.73%200%200%200-1.72-1.739zM9.87%203.605a.468.468%200%200%201%20.932%200V9.79a.468.468%200%200%201-.932%200zM7.542%203.38a.468.468%200%200%201%20.933%200v6.7a.468.468%200%200%201-.933%200zm-2.335.225a.468.468%200%200%201%20.932%200V9.79a.468.468%200%200%201-.932%200zm-2.337.932a.468.468%200%200%201%20.93%200v4.159a.468.468%200%200%201-.932%200zm10.114%207.048a7.97%207.97%200%200%201-4.97%201.491%208.04%208.04%200%200%201-4.97-1.491.465.465%200%201%201%20.606-.707%207.22%207.22%200%200%200%204.364%201.28%207.13%207.13%200%200%200%204.364-1.271.47.47%200%200%201%20.772.37.45.45%200%200%201-.146.312l-.018.016zm.158-2.89a.468.468%200%200%201-.932%200V4.538a.468.468%200%200%201%20.932%200z%22%2F%3E%3C%2Fg%3E%3Cdefs%3E%3CclipPath%20id%3D%22f9a97_a%22%3E%3Cpath%20fill%3D%22%23fff%22%20d%3D%22M1%201h14v14H1z%22%2F%3E%3C%2FclipPath%3E%3C%2Fdefs%3E%3C%2Fsvg%3E)


%22%3E%3Cpath%20fill%3D%22%23067DE5%22%20d%3D%22M6.823%204.17a2.47%202.47%200%200%201%201.778-.765%202.48%202.48%200%200%201%202.16%201.282c.385-.172.803-.26%201.225-.259%201.67%200%203.019%201.363%203.019%203.044%200%201.68-1.357%203.044-3.024%203.044q-.299%200-.592-.06a2.21%202.21%200%200%201-2.893.913%202.515%202.515%200%200%201-4.68-.113A2.35%202.35%200%200%201%201%208.938%202.37%202.37%200%200%201%202.17%206.89a2.713%202.713%200%200%201%202.489-3.793A2.72%202.72%200%200%201%206.823%204.17%22%2F%3E%3C%2Fg%3E%3Cdefs%3E%3CclipPath%20id%3D%22fa7cb_a%22%3E%3Cpath%20fill%3D%22%23fff%22%20d%3D%22M1%201h14v14H1z%22%2F%3E%3C%2FclipPath%3E%3C%2Fdefs%3E%3C%2Fsvg%3E)



%22%3E%3Cpath%20fill%3D%22%23067DE5%22%20d%3D%22m12.856%2011.71-2.92-1.687a.86.86%200%200%200-1.282.827v3.296a.855.855%200%200%200%201.709%200v-1.895l1.635.944a.858.858%200%200%200%20.858-1.485M5.595%208.096a.84.84%200%200%200-.419-.741L2.256%205.67a.838.838%200%200%200-.836%201.45l1.683.971-1.683.972a.83.83%200%200%200-.39.508.84.84%200%200%200%201.228.943L5.175%208.83a.84.84%200%200%200%20.419-.734m-2.676-3.62%202.92%201.685c.34.197.76.133%201.029-.13a.85.85%200%200%200%20.276-.629V2.024a.855.855%200%201%200-1.71%200v1.923L3.778%202.99a.858.858%200%201%200-.858%201.485m6.565%203.757a.33.33%200%200%201-.083.202L8.244%209.59a.33.33%200%200%201-.202.083h-.294a.33.33%200%200%201-.202-.083L6.388%208.434a.33.33%200%200%201-.083-.202v-.294c0-.066.037-.155.083-.201l1.158-1.159a.33.33%200%200%201%20.202-.083h.294c.065%200%20.156.037.202.083L9.4%207.737a.33.33%200%200%201%20.083.2zM8.45%208.091v-.013a.25.25%200%200%200-.06-.148l-.343-.34a.23.23%200%200%200-.148-.062h-.012a.24.24%200%200%200-.148.062l-.34.34a.24.24%200%200%200-.061.148v.013a.24.24%200%200%200%20.06.148l.341.341c.035.034.1.061.148.061H7.9a.24.24%200%200%200%20.148-.06l.342-.342a.24.24%200%200%200%20.061-.148m1.485-1.93%202.92-1.686a.858.858%200%201%200-.858-1.485l-1.635.945v-1.91a.855.855%200%201%200-1.71%200v3.31a.858.858%200%200%200%201.283.825M6.424%209.925a.85.85%200%200%200-.586.1L2.92%2011.71a.856.856%200%201%200%20.858%201.485l1.658-.957v1.908a.855.855%200%200%200%201.709%200v-3.378a.855.855%200%200%200-.72-.844m8.256-3.957a.857.857%200%200%200-1.172-.315l-2.92%201.686a.86.86%200%200%200-.428.758c-.002.3.152.591.429.75l2.92%201.687a.86.86%200%200%200%20.857-1.486l-1.653-.955%201.653-.955a.855.855%200%200%200%20.315-1.17%22%2F%3E%3C%2Fg%3E%3Cdefs%3E%3CclipPath%20id%3D%22c5b82_a%22%3E%3Cpath%20fill%3D%22%23fff%22%20d%3D%22M1%201h14v14H1z%22%2F%3E%3C%2FclipPath%3E%3C%2Fdefs%3E%3C%2Fsvg%3E)










%22%3E%3Cpath%20fill%3D%22%23007FD2%22%20d%3D%22m8.235%207.317-2.229-.034h-.37c.415-1.635.93-2.878%201.3-3.17a.2.2%200%200%201%20.1-.033.16.16%200%200%201%20.135.078c.223.394.396.815.515%201.252.168.518.348%201.156.55%201.907%22%2F%3E%3Cpath%20fill%3D%22%23007FD2%22%20d%3D%22M7.686%205.41c.168.515.35%201.153.55%201.904l-2.23-.031h-.37c.415-1.635.93-2.878%201.3-3.17a.2.2%200%200%201%20.1-.033.16.16%200%200%201%20.135.078c.223.394.396.815.515%201.252%22%2F%3E%3Cpath%20fill%3D%22%23067DE5%22%20d%3D%22M8%201a7%207%200%201%200%200%2014A7%207%200%200%200%208%201m5.029%207.134c-.011.012-.023.012-.023.023h-.01l-.012.011-.011.011a.5.5%200%200%201-.168.045H9.478c.023.112.056.235.09.37.18.784.66%202.878%201.176%202.878h.022c.404%200%20.605-.582%201.05-1.848V9.61c.07-.202.157-.437.247-.672l.022-.07a.16.16%200%200%201%20.303.1l-.023.07c-.045.146-.1.36-.157.594-.268%201.11-.672%202.778-1.702%202.778h-.011c-.672%200-1.064-1.075-1.243-1.534a27%2027%200%200%201-.796-2.644H5.424l-.638%202.03-.012-.01a.336.336%200%200%201-.448.1.32.32%200%200%201-.145-.269v-.011l.033-.224c.09-.526.19-1.064.314-1.61H3.251a.484.484%200%200%201-.414-.482.49.49%200%200%201%20.392-.481c.045%200%20.1-.011.145-.011h.07c.404.01.84.01%201.322.022.672-2.73%201.456-4.122%202.318-4.122.93%200%201.61%202.117%202.162%204.178v.011c1.131.023%202.34.056%203.506.146h.112a.37.37%200%200%201%20.248.549.3.3%200%200%201-.083.086%22%2F%3E%3Cpath%20fill%3D%22%23067DE5%22%20d%3D%22m8.235%207.317-2.229-.034h-.37c.415-1.635.93-2.878%201.3-3.17a.2.2%200%200%201%20.1-.033.16.16%200%200%201%20.135.078c.223.394.396.815.515%201.252.168.518.348%201.156.55%201.907%22%2F%3E%3C%2Fg%3E%3Cdefs%3E%3CclipPath%20id%3D%220de1d_a%22%3E%3Cpath%20fill%3D%22%23fff%22%20d%3D%22M1%201h14v14H1z%22%2F%3E%3C%2FclipPath%3E%3C%2Fdefs%3E%3C%2Fsvg%3E)


%22%3E%3Cpath%20fill%3D%22%23FF4600%22%20d%3D%22M2.346%2012.722a2.76%202.76%200%200%201%20.07-2.71L6.66%202.944c.404-.673%201.133-1.098%201.81-.845q.06.022.119.048c.29.126.516.384.696.673l.481.773a.38.38%200%200%201%20.021.354c-.077.17-.26.232-.406.138l-.583-.379a.52.52%200%200%200-.455-.06.6.6%200%200%200-.32.267l-4.256%207.154a.8.8%200%200%200-.02.77c.225.43.775.469%201.045.076L8.78%206.11c.661-.963%201.945-.92%202.555.086l2.26%203.721a2.84%202.84%200%200%201%20.22%202.472c-.735%201.987-3.083%202.135-4.083.308a9%209%200%200%201-.203-.395%201.62%201.62%200%200%201%20.202-1.705.225.225%200%200%201%20.36.008c.222.285.626.792%201.028%201.253.473.543%201.032.444%201.247-.098.1-.252.015-.56-.112-.77l-2.095-3.45c-.066-.108-.204-.113-.275-.01l-3.808%205.463c-.979%201.424-2.917%201.284-3.73-.27%22%2F%3E%3C%2Fg%3E%3Cdefs%3E%3CclipPath%20id%3D%22016b0_a%22%3E%3Cpath%20fill%3D%22%23fff%22%20d%3D%22M14%202H2v12h12z%22%2F%3E%3C%2FclipPath%3E%3C%2Fdefs%3E%3C%2Fsvg%3E)


%22%20d%3D%22M11.955%208.38a3.045%203.045%200%201%200%200%206.092%203.045%203.045%200%200%200%200-6.092m-7.91%200a3.045%203.045%200%201%200%200%206.09%203.045%203.045%200%200%200%200-6.09m7-3.805a3.045%203.045%200%201%201-6.088%200%203.045%203.045%200%200%201%206.087%200z%22%2F%3E%3Cdefs%3E%3CradialGradient%20id%3D%2208d80_a%22%20cx%3D%220%22%20cy%3D%220%22%20r%3D%221%22%20gradientTransform%3D%22matrix(9.2812%200%200%208.57864%207.988%208.673)%22%20gradientUnits%3D%22userSpaceOnUse%22%3E%3Cstop%20stop-color%3D%22%23FFB900%22%2F%3E%3Cstop%20offset%3D%22.6%22%20stop-color%3D%22%23F95D8F%22%2F%3E%3Cstop%20offset%3D%22.999%22%20stop-color%3D%22%23F95353%22%2F%3E%3C%2FradialGradient%3E%3C%2Fdefs%3E%3C%2Fsvg%3E)




%22%20clip-rule%3D%22evenodd%22%3E%3Cpath%20d%3D%22M10.854%209.187a1.603%201.603%200%200%201-1.67%201.683%201.657%201.657%200%200%201-1.668-1.666%201.67%201.67%200%201%201%203.339-.018z%22%2F%3E%3Cpath%20d%3D%22M10.854%209.187a1.603%201.603%200%200%201-1.67%201.683%201.657%201.657%200%200%201-1.668-1.666%201.67%201.67%200%201%201%203.339-.018z%22%2F%3E%3Cpath%20d%3D%22M8%201a7%207%200%201%200%200%2014A7%207%200%200%200%208%201M5.947%207.61a3%203%200%200%201-.813-.245%203%203%200%200%201-1.063-.958q-.524-.584-1.125-1.088.248.02.49.077c.44.124.868.293%201.274.504.121.062.188.104.307.176q.303.2.553.463c.213.217.4.391.56.585a9.6%209.6%200%200%200-1.508-2.426c.29.134.558.313.794.53.388.397.659.893.784%201.434l.32%201.046s-.315-.058-.573-.098m3.238%203.92A2.24%202.24%200%200%201%206.86%209.248V4.676h.72v2.791l.085-.09a2.07%202.07%200%200%201%201.595-.596%202.373%202.373%200%201%201-.07%204.746zm.016-4.06a1.65%201.65%200%200%200-1.685%201.734%201.66%201.66%200%200%200%201.668%201.666%201.6%201.6%200%200%200%201.67-1.685A1.65%201.65%200%200%200%209.2%207.465z%22%2F%3E%3C%2Fg%3E%3Cdefs%3E%3CclipPath%20id%3D%22a4877_a%22%3E%3Cpath%20fill%3D%22%23fff%22%20d%3D%22M1%201h14v14H1z%22%2F%3E%3C%2FclipPath%3E%3C%2Fdefs%3E%3C%2Fsvg%3E)











%22%3E%3Cpath%20fill%3D%22%23067DE5%22%20d%3D%22M10.596%2010.076c-.453.394-1.017.884-2.044.884h-.613c-.742%200-1.417-.264-1.9-.744a2.52%202.52%200%200%201-.732-1.806v-.823c0-.696.26-1.338.732-1.807.483-.48%201.158-.744%201.9-.744h.613c1.027%200%201.591.491%202.044.884.47.41.877.763%201.958.763q.252%200%20.493-.04l-.004-.009a4%204%200%200%200-.228-.458l-.723-1.229a3.73%203.73%200%200%200-3.216-1.821H7.429a3.73%203.73%200%200%200-3.217%201.821l-.724%201.23a3.58%203.58%200%200%200%200%203.643l.724%201.23a3.73%203.73%200%200%200%203.217%201.82h1.447a3.73%203.73%200%200%200%203.216-1.82l.723-1.23a4%204%200%200%200%20.228-.458l.003-.01a3%203%200%200%200-.492-.038c-1.081%200-1.487.353-1.958.761%22%2F%3E%3Cpath%20fill%3D%22%23006BFF%22%20d%3D%22M8.552%205.782h-.613c-1.13%200-1.873.792-1.873%201.804v.824c0%201.013.743%201.804%201.873%201.804h.612c1.646%200%201.518-1.646%204.002-1.646q.358%200%20.703.063a3.6%203.6%200%200%200%200-1.266%204%204%200%200%201-.703.063c-2.485%200-2.356-1.646-4.001-1.646%22%2F%3E%3Cpath%20fill%3D%22%23067DE5%22%20d%3D%22M14.683%209.233a3.5%203.5%200%200%200-1.427-.602l-.002.012a3.6%203.6%200%200%201-.208.71c.425.063.83.226%201.18.475l-.003.012a6.2%206.2%200%200%201-.887%201.765%206.4%206.4%200%200%201-5.204%202.643c-.86%200-1.695-.166-2.48-.491a6.4%206.4%200%200%201-2.026-1.34%206.2%206.2%200%200%201-1.365-1.987%206.1%206.1%200%200%201-.5-2.432c0-.845.168-1.663.5-2.433a6.2%206.2%200%200%201%201.365-1.988%206.4%206.4%200%200%201%202.026-1.34%206.4%206.4%200%200%201%202.48-.49%206.4%206.4%200%200%201%205.206%202.642c.388.537.687%201.133.886%201.765l.003.012a2.74%202.74%200%200%201-1.18.476q.14.348.207.71l.002.012a3.5%203.5%200%200%200%201.428-.602c.406-.296.328-.63.266-.827C14.053%203.077%2011.34%201%208.132%201%204.193%201%201%204.133%201%207.997s3.193%206.996%207.132%206.996c3.208%200%205.92-2.077%206.818-4.935.062-.197.14-.53-.267-.825%22%2F%3E%3Cpath%20fill%3D%22%230AE8F0%22%20d%3D%22M13.046%206.643a3%203%200%200%201-.493.039c-1.081%200-1.488-.353-1.957-.762-.453-.394-1.018-.884-2.044-.884h-.613c-.743%200-1.418.264-1.9.744a2.52%202.52%200%200%200-.733%201.806v.824c0%20.695.26%201.337.732%201.806.483.48%201.158.743%201.9.743h.613c1.028%200%201.592-.49%202.045-.884.47-.408.876-.762%201.957-.762q.252%200%20.493.039a3.6%203.6%200%200%200%20.208-.71l.002-.01a4%204%200%200%200-.703-.065c-2.485%200-2.356%201.647-4.002%201.647H7.94c-1.13%200-1.873-.791-1.873-1.804v-.825c0-1.012.743-1.804%201.873-1.804h.612c1.646%200%201.517%201.646%204.002%201.646q.358%200%20.703-.063l-.002-.011a3.6%203.6%200%200%200-.208-.71%22%2F%3E%3Cpath%20fill%3D%22%230AE8F0%22%20d%3D%22M13.046%206.643a3%203%200%200%201-.493.039c-1.081%200-1.488-.353-1.957-.762-.453-.394-1.018-.884-2.044-.884h-.613c-.743%200-1.418.264-1.9.744a2.52%202.52%200%200%200-.733%201.806v.824c0%20.695.26%201.337.732%201.806.483.48%201.158.743%201.9.743h.613c1.028%200%201.592-.49%202.045-.884.47-.408.876-.762%201.957-.762q.252%200%20.493.039a3.6%203.6%200%200%200%20.208-.71l.002-.01a4%204%200%200%200-.703-.065c-2.485%200-2.356%201.647-4.002%201.647H7.94c-1.13%200-1.873-.791-1.873-1.804v-.825c0-1.012.743-1.804%201.873-1.804h.612c1.646%200%201.517%201.646%204.002%201.646q.358%200%20.703-.063l-.002-.011a3.6%203.6%200%200%200-.208-.71%22%2F%3E%3C%2Fg%3E%3Cdefs%3E%3CclipPath%20id%3D%223ec8a_a%22%3E%3Cpath%20fill%3D%22%23fff%22%20d%3D%22M1%201h14v14H1z%22%2F%3E%3C%2FclipPath%3E%3C%2Fdefs%3E%3C%2Fsvg%3E)

%22%3E%3Cpath%20d%3D%22M14.904%203.46a.53.53%200%200%200-.742-.132l-13.066%209.15a.53.53%200%200%200%20.435.226h12.937a.53.53%200%200%200%20.532-.532V3.756a.53.53%200%200%200-.096-.296M1.838%203.328A.533.533%200%200%200%201%203.756v8.432l6.22-5.096z%22%2F%3E%3C%2Fg%3E%3Cdefs%3E%3CclipPath%20id%3D%225c2e6_a%22%3E%3Cpath%20fill%3D%22%23fff%22%20d%3D%22M1%203.232h14v9.481H1z%22%2F%3E%3C%2FclipPath%3E%3C%2Fdefs%3E%3C%2Fsvg%3E)






















%22%3E%3Cg%20clip-path%3D%22url(%23a1d9b_b)%22%3E%3Cpath%20fill%3D%22%23596CDC%22%20d%3D%22M16%200a7.87%207.87%200%200%201-7.871%207.871H0V0z%22%2F%3E%3Cpath%20fill%3D%22%2373D7BF%22%20fill-rule%3D%22evenodd%22%20d%3D%22M0%2016A8.001%208.001%200%200%200%200%200z%22%20clip-rule%3D%22evenodd%22%2F%3E%3Cpath%20fill%3D%22%230D2437%22%20fill-rule%3D%22evenodd%22%20d%3D%22M0%200a8%208%200%200%201%207.869%207.869H0z%22%20clip-rule%3D%22evenodd%22%2F%3E%3C%2Fg%3E%3C%2Fg%3E%3Cdefs%3E%3CclipPath%20id%3D%22a1d9b_a%22%3E%3Cpath%20fill%3D%22%23fff%22%20d%3D%22M0%200h16v16H0z%22%2F%3E%3C%2FclipPath%3E%3CclipPath%20id%3D%22a1d9b_b%22%3E%3Cpath%20fill%3D%22%23fff%22%20d%3D%22M0%200h16v16H0z%22%2F%3E%3C%2FclipPath%3E%3C%2Fdefs%3E%3C%2Fsvg%3E)





%22%3E%3Cpath%20fill-rule%3D%22evenodd%22%20d%3D%22M8%201.173a7%207%200%200%200-2.213%2013.642c.35.065.478-.152.478-.336%200-.167-.006-.719-.01-1.304-1.947.42-2.358-.826-2.358-.826a1.85%201.85%200%200%200-.777-1.024c-.635-.435.048-.426.048-.426a1.47%201.47%200%200%201%201.073.722%201.49%201.49%200%200%200%202.037.579%201.5%201.5%200%200%201%20.445-.936c-1.555-.177-3.19-.777-3.19-3.46a2.7%202.7%200%200%201%20.721-1.876%202.52%202.52%200%200%201%20.07-1.852s.588-.189%201.926.717a6.64%206.64%200%200%201%203.506%200c1.336-.906%201.922-.717%201.922-.717.26.586.284%201.248.07%201.852.473.51.73%201.184.718%201.88%200%202.688-1.637%203.28-3.196%203.453a1.67%201.67%200%200%201%20.474%201.297c0%20.936-.007%201.69-.007%201.92%200%20.187.126.405.48.337A7%207%200%200%200%208%201.173%22%20clip-rule%3D%22evenodd%22%2F%3E%3Cpath%20d%3D%22M3.651%2011.22c-.015.035-.07.045-.12.022-.049-.024-.078-.07-.062-.105s.07-.046.12-.022.08.07.062.106zm.284.32c-.034.03-.099.016-.14-.033a.107.107%200%200%201-.02-.146c.034-.03.098-.016.143.032.046.049.055.115.02.146zm.275.402c-.042.03-.113%200-.155-.06-.043-.06-.043-.14%200-.166.042-.027.112%200%20.157.058.044.06.042.14%200%20.169zm.379.39c-.039.042-.12.031-.18-.026a.134.134%200%200%201-.04-.179c.04-.042.121-.03.181.027s.08.14.039.179m.521.225c-.016.055-.096.08-.175.057s-.13-.088-.114-.143c.016-.056.095-.082.175-.056.08.025.13.087.114.14zm.574.042c0%20.058-.065.106-.149.107-.083%200-.15-.045-.152-.102s.066-.105.149-.107c.083-.001.151.045.151.102m.533-.09c.01.055-.047.114-.13.129-.082.015-.156-.02-.166-.076s.049-.115.13-.13.157.02.167.077%22%2F%3E%3C%2Fg%3E%3Cdefs%3E%3CclipPath%20id%3D%22a5da3_a%22%3E%3Cpath%20fill%3D%22%23fff%22%20d%3D%22M1%201h14v14H1z%22%2F%3E%3C%2FclipPath%3E%3C%2Fdefs%3E%3C%2Fsvg%3E)
%22%3E%3Cpath%20fill%3D%22%23E24329%22%20d%3D%22m8%2014.481%202.576-7.964H5.424z%22%2F%3E%3Cpath%20fill%3D%22%23FCA326%22%20d%3D%22m1.815%206.517-.787%202.419a.524.524%200%200%200%20.194.598L8%2014.478z%22%2F%3E%3Cpath%20fill%3D%22%23E24329%22%20d%3D%22M1.815%206.517h3.609l-1.554-4.8a.263.263%200%200%200-.509%200z%22%2F%3E%3Cpath%20fill%3D%22%23FCA326%22%20d%3D%22m14.185%206.517.787%202.419a.524.524%200%200%201-.194.598L8%2014.48z%22%2F%3E%3Cpath%20fill%3D%22%23E24329%22%20d%3D%22M14.185%206.517h-3.61l1.555-4.8a.263.263%200%200%201%20.509%200z%22%2F%3E%3Cpath%20fill%3D%22%23FC6D26%22%20d%3D%22m8%2014.481%202.576-7.964h3.61zm0%200L1.815%206.517h3.609z%22%2F%3E%3C%2Fg%3E%3Cdefs%3E%3CclipPath%20id%3D%22a4708_a%22%3E%3Cpath%20fill%3D%22%23fff%22%20d%3D%22M1%201h14v14H1z%22%2F%3E%3C%2FclipPath%3E%3C%2Fdefs%3E%3C%2Fsvg%3E)



%22%3E%3Cpath%20fill%3D%22%23E1F0FF%22%20d%3D%22M2.017%204.413h11.966v7.478H2.017z%22%2F%3E%3Cpath%20fill%3D%22%23B7D9F8%22%20d%3D%22M13.983%204.413H2.017V2.915c0-.55.448-.995%201-.995h9.966c.552%200%201%20.445%201%20.995z%22%2F%3E%3Cpath%20fill%3D%22%23fff%22%20d%3D%22M5.009%203.665a.499.499%200%201%201%200-.997.499.499%200%200%201%200%20.997m-1.745%200a.499.499%200%201%201%200-.997.499.499%200%200%201%200%20.997%22%2F%3E%3Cpath%20fill%3D%22%230080F1%22%20d%3D%22M4.012%2011.891H2.017a5.983%205.983%200%200%201%2010.213-4.23l-1.41%201.41a3.988%203.988%200%200%200-6.809%202.82%22%2F%3E%3Cpath%20fill%3D%22%23BF7AF0%22%20d%3D%22M11.988%2011.892h1.995a5.96%205.96%200%200%200-1.753-4.23l-1.41%201.41a3.98%203.98%200%200%201%201.168%202.82%22%2F%3E%3Cpath%20fill%3D%22%2396C7F2%22%20d%3D%22M6.59%2013.301a1.994%201.994%200%200%201%200-2.82c.779-.779%205.112-2.292%205.112-2.292s-1.513%204.333-2.292%205.112a1.994%201.994%200%200%201-2.82%200%22%2F%3E%3Cpath%20fill%3D%22%2306F%22%20d%3D%22M8%2012.888a.997.997%200%201%201%200-1.994.997.997%200%200%201%200%201.994%22%2F%3E%3C%2Fg%3E%3C%2Fsvg%3E)





%22%3E%3Cpath%20fill%3D%22%23E54D2E%22%20d%3D%22M15.904%205.016c-.078-1.081-.09-2.2-.765-2.984A3.6%203.6%200%200%200%2013.314.865c-1.319-.382-2.486-.35-3.83-.387-2.944-.084-5.768-.261-7.588.53C.044%201.614-.08%206.046.028%207.917c.075%201.326.057%203.274.639%204.512.782%201.666%202.52%201.662%204.165%201.862.784.096%203.157.123%203.979.125.326.523%201.236.908%201.632%201.147.397.239%201.703.573%201.798.275.096-.297-.513-.892-.291-1.73%201.1-.223%201.42-.117%202.174-.355%201.14-.361%201.561-1.708%201.76-3.147.185-1.33.116-4.253.02-5.59%22%2F%3E%3Cpath%20fill%3D%22%23fff%22%20d%3D%22M7.605%208.683c.063.448.11%202.417.178%203.044.01.134.048.21.183.207q.162.016.581.016c.328%200%20.659-.009.932-.01.47.005.244-.878.248-1.362-.045-.935-.074-3.241-.126-4.294-.007-.221-.037-1.936-.054-2.324-.01-.166.023-.54-.032-.657-.066-.107-.36-.14-.527-.128-.434%200-.794.005-1.14.06-.31.05-.428.168-.434.435-.002.08.005.602.011%201.155.006.512.015%201.055.015%201.344-.012.29-.506.14-.786.176-.457-.01-1.615.028-1.845.041-.14-.003-.154-.123-.183-.26-.064-.63-.14-1.6-.17-2.261-.011-.362-.03-.662-.146-.68-.301-.056-1.692-.038-1.771.113-.07.206-.048.694-.043%201.045.015%201.79.174%203.963.2%205.69.018.525.03%201.607.03%201.664.002.18.022.228.201.247.561.031%201.247-.012%201.81.003.29.019.15-.517.184-.731a22%2022%200%200%200-.05-1.66c-.023-.94-.277-.931.683-.98.167-.012.954-.04%201.417-.05.298.023.529-.12.634.157%22%2F%3E%3Cpath%20fill%3D%22%23fff%22%20fill-rule%3D%22evenodd%22%20d%3D%22M13.234%203.892c-.06-.547-.458-.914-.99-.914q-.225%200-.454.084a1%201%200%200%200-.229.124%201.12%201.12%200%200%200-.444%201.011.97.97%200%200%200%20.591.806c.158.068.353.108.533.108.162%200%20.394-.03.577-.177.341-.276.465-.588.416-1.042%22%20clip-rule%3D%22evenodd%22%2F%3E%3Cpath%20fill%3D%22%23fff%22%20d%3D%22M13.244%207.725c0-.42-.01-.719-.001-1.156.036-.48-.486-.377-.849-.39-.279%200-.556.005-.822.005-.166.007-.244.015-.235.16-.09%201.821-.011%202.985-.043%204.706-.027%201.168.007.825%201.015.891.226.004.66.048.833-.04.087-.06.066-.157.087-.287-.01-1.69.003-1.824.015-3.89%22%2F%3E%3C%2Fg%3E%3Cdefs%3E%3CclipPath%20id%3D%220667f_a%22%3E%3Cpath%20fill%3D%22%23fff%22%20d%3D%22M0%200h16v16H0z%22%2F%3E%3C%2FclipPath%3E%3C%2Fdefs%3E%3C%2Fsvg%3E)





%22%20d%3D%22M8%205.867A3.585%203.585%200%200%201%207.985.804L3.303%205.469l2.548%202.54z%22%2F%3E%3Cpath%20fill%3D%22%230F61BB%22%20d%3D%22M10.145%207.994%208%2010.134a3.587%203.587%200%200%201%200%205.078l4.695-4.677z%22%2F%3E%3Cdefs%3E%3ClinearGradient%20id%3D%2287354_a%22%20x1%3D%224.515%22%20x2%3D%226.782%22%20y1%3D%226.67%22%20y2%3D%224.422%22%20gradientUnits%3D%22userSpaceOnUse%22%3E%3Cstop%20stop-color%3D%22%23067DE5%22%2F%3E%3Cstop%20offset%3D%221%22%20stop-color%3D%22%230666CE%22%2F%3E%3C%2FlinearGradient%3E%3C%2Fdefs%3E%3C%2Fsvg%3E)














%22%20d%3D%22M1.597%204.419h5.969a.597.597%200%200%201%20.597.597v5.969a.597.597%200%200%201-.597.597H1.597A.597.597%200%200%201%201%2010.985v-5.97a.597.597%200%200%201%20.597-.596%22%2F%3E%3Cpath%20fill%3D%22%23fff%22%20d%3D%22M6.152%206.69h-1.19v3.25h-.764V6.69h-1.19v-.63h3.144z%22%2F%3E%3Cdefs%3E%3ClinearGradient%20id%3D%227212b_a%22%20x1%3D%222.245%22%20x2%3D%226.919%22%20y1%3D%223.952%22%20y2%3D%2212.047%22%20gradientUnits%3D%22userSpaceOnUse%22%3E%3Cstop%20stop-color%3D%22%235A62C3%22%2F%3E%3Cstop%20offset%3D%22.5%22%20stop-color%3D%22%234D55BD%22%2F%3E%3Cstop%20offset%3D%221%22%20stop-color%3D%22%233940AB%22%2F%3E%3C%2FlinearGradient%3E%3C%2Fdefs%3E%3C%2Fsvg%3E)
%22%3E%3Cpath%20d%3D%22M4.034%208a2.017%202.017%200%201%201-2.017-2.017h.007a2.015%202.015%200%200%201%202.018%202.012V8m6.731.035a1.44%201.44%200%201%201-2.88%200%201.44%201.44%200%200%201%202.88%200m5.227%200a.647.647%200%201%201-.647-.647.645.645%200%200%201%20.647.64v.005%22%2F%3E%3C%2Fg%3E%3Cdefs%3E%3CclipPath%20id%3D%2266bab_a%22%3E%3Cpath%20fill%3D%22%23fff%22%20d%3D%22M0%200h16v16H0z%22%2F%3E%3C%2FclipPath%3E%3C%2Fdefs%3E%3C%2Fsvg%3E)

%22%3E%3Cpath%20fill%3D%22%23297C3B%22%20d%3D%22m7.95.043.427.802c.096.148.2.28.322.401q.54.534%201.002%201.133c.724.95%201.212%202.005%201.56%203.146a7.7%207.7%200%200%201%20.331%202.135c.035%202.162-.706%204.018-2.2%205.56a6.4%206.4%200%200%201-.785.672c-.148%200-.218-.114-.279-.218a1.8%201.8%200%200%201-.218-.628%203%203%200%200%201-.07-.793v-.122C8.028%2012.105%207.898.105%207.95.043%22%2F%3E%3Cpath%20fill%3D%22%2346A758%22%20d%3D%22M7.95.017c-.017-.035-.035-.009-.052.008a.8.8%200%200%201-.148.48c-.105.148-.244.262-.384.384-.775.671-1.385%201.481-1.873%202.388-.65%201.22-.985%202.527-1.08%203.904-.044.496.157%202.248.313%202.754.427%201.342%201.194%202.467%202.188%203.442.244.236.505.454.775.663.078%200%20.087-.07.105-.122a2.4%202.4%200%200%200%20.078-.34l.175-1.307z%22%2F%3E%3Cpath%20fill%3D%22%23C2BFBF%22%20d%3D%22M8.377%2014.423c.017-.2.113-.366.218-.532a.55.55%200%200%201-.244-.226%201.6%201.6%200%200%201-.13-.288c-.122-.366-.148-.75-.183-1.124v-.226c-.044.035-.053.33-.053.375a9%209%200%200%201-.157%201.176c-.026.157-.043.314-.14.453%200%20.018%200%20.035.009.061.157.462.2.933.226%201.412v.175c0%20.21-.008.165.165.235.07.026.148.035.218.087.053%200%20.061-.043.061-.078l-.026-.288v-.802c-.008-.14.018-.279.035-.41z%22%2F%3E%3C%2Fg%3E%3Cdefs%3E%3CclipPath%20id%3D%22190ec_a%22%3E%3Cpath%20fill%3D%22%23fff%22%20d%3D%22M0%200h16v16H0z%22%2F%3E%3C%2FclipPath%3E%3C%2Fdefs%3E%3C%2Fsvg%3E)




















%22%3E%3Cg%20fill%3D%22%23000%22%20fill-rule%3D%22evenodd%22%20clip-rule%3D%22evenodd%22%20opacity%3D%22.2%22%3E%3Cpath%20d%3D%22M15.938%205.902c-.853.813-2.492%201.365-4.382%201.365-1.406%200-2.676-.31-3.587-.803-1.047-.571-2.492-1.365-4.382-1.365-1.406%200-2.676.31-3.587.803v-.387c.911-.493%202.181-.803%203.587-.803%201.89%200%203.335.794%204.382%201.365.911.493%202.181.803%203.587.803%201.89%200%203.529-.552%204.382-1.365z%22%2F%3E%3Cpath%20d%3D%22M15.938%207.548c-.853.813-2.492%201.364-4.382%201.364-1.406%200-2.676-.31-3.587-.803-1.047-.571-2.492-1.365-4.382-1.365-1.406%200-2.676.31-3.587.804V7.16c.911-.493%202.181-.803%203.587-.803%201.89%200%203.335.794%204.382%201.365.911.493%202.181.803%203.587.803%201.89%200%203.529-.552%204.382-1.365z%22%2F%3E%3Cpath%20d%3D%22M15.938%209.194c-.853.813-2.492%201.364-4.382%201.364-1.406%200-2.676-.31-3.587-.803C6.922%209.184%205.477%208.39%203.587%208.39%202.18%208.39.91%208.7%200%209.193v-.387c.911-.493%202.181-.803%203.587-.803%201.89%200%203.335.794%204.382%201.365.911.493%202.181.803%203.587.803%201.89%200%203.529-.552%204.382-1.365z%22%2F%3E%3Cpath%20d%3D%22M15.938%2010.839c-.853.813-2.492%201.364-4.382%201.364-1.406%200-2.676-.31-3.587-.803-1.047-.571-2.492-1.365-4.382-1.365-1.406%200-2.676.31-3.587.803v-.387c.911-.493%202.181-.803%203.587-.803%201.89%200%203.335.794%204.382%201.365.911.493%202.181.803%203.587.803%201.89%200%203.529-.552%204.382-1.365z%22%2F%3E%3C%2Fg%3E%3Cpath%20fill%3D%22%23171717%22%20d%3D%22M3.648%2012.747h.722a.556.556%200%200%200%20.599-.598V3.852a.553.553%200%200%200-.599-.598h-.722V1.408h5.249c2.818%200%205.055%201.424%205.055%204.149s-2.237%204.166-5.055%204.166H7.1v2.426a.558.558%200%200%200%20.617.598h1.462v1.845H3.648zm5.09-4.958c1.867%200%202.942-.773%202.942-2.214%200-1.46-1.075-2.216-2.941-2.216H7.1v4.43z%22%2F%3E%3C%2Fg%3E%3C%2Fsvg%3E)

%22%3E%3Cpath%20fill%3D%22%23E8E8E8%22%20d%3D%22M15.104%203.394%208%206.85.93%203.335%208.032.96z%22%2F%3E%3Cpath%20fill%3D%22%23F2F0F0%22%20d%3D%22m15.104%203.394-.033%208.19-7.104%203.456L8%206.85z%22%2F%3E%3Cpath%20fill%3D%22%23DDD%22%20d%3D%22m8%206.851-.033%208.189-7.071-3.515.033-8.19z%22%2F%3E%3C%2Fg%3E%3Cdefs%3E%3CclipPath%20id%3D%2298032_a%22%3E%3Cpath%20fill%3D%22%23fff%22%20d%3D%22M0%200h16v16H0z%22%2F%3E%3C%2FclipPath%3E%3C%2Fdefs%3E%3C%2Fsvg%3E)




















%22%3E%3Cpath%20fill%3D%22%23171717%22%20fill-rule%3D%22evenodd%22%20d%3D%22M1.051%2012.301h3.348C16.055.59%2033.2-.654%2035.173-.759l.187-.01-.187.01C13.169.294%203.038%209.667.768%2011.858zM4.95%204.032h-3.7l-.202.382%204.11%202.995a41%2041%200%200%201%202.547-1.358zm3.316%205.642%203.612%202.633h3.746l.155-.349-5.394-3.946a42%2042%200%200%200-2.12%201.662%22%20clip-rule%3D%22evenodd%22%2F%3E%3C%2Fg%3E%3Cdefs%3E%3CclipPath%20id%3D%2221eb8_a%22%3E%3Cpath%20fill%3D%22%23fff%22%20d%3D%22M0%200h16v16H0z%22%2F%3E%3C%2FclipPath%3E%3C%2Fdefs%3E%3C%2Fsvg%3E)



























Connecting people with their data. Empathy-driven design at Tably.
By David Laban, Rust Engineer
26 Sep, 2022
User-Friendly Setup Flows
If you want people to use your tool for data work, they will need to connect your tool to their data. You can build the most beautiful and performant tool in the world, but if people can’t connect it to their data, they will not use it.
There are two extremes when it comes to connecting data tools together. On one extreme there is Singer , which takes the “configuration as code” approach, targeting the data-engineer persona.
On the other extreme, you have no-code Zapier and data warehouse-oriented Fivetran , which provide graphical setup flows for people to connect their tools together, and hold their hand throughout the process.
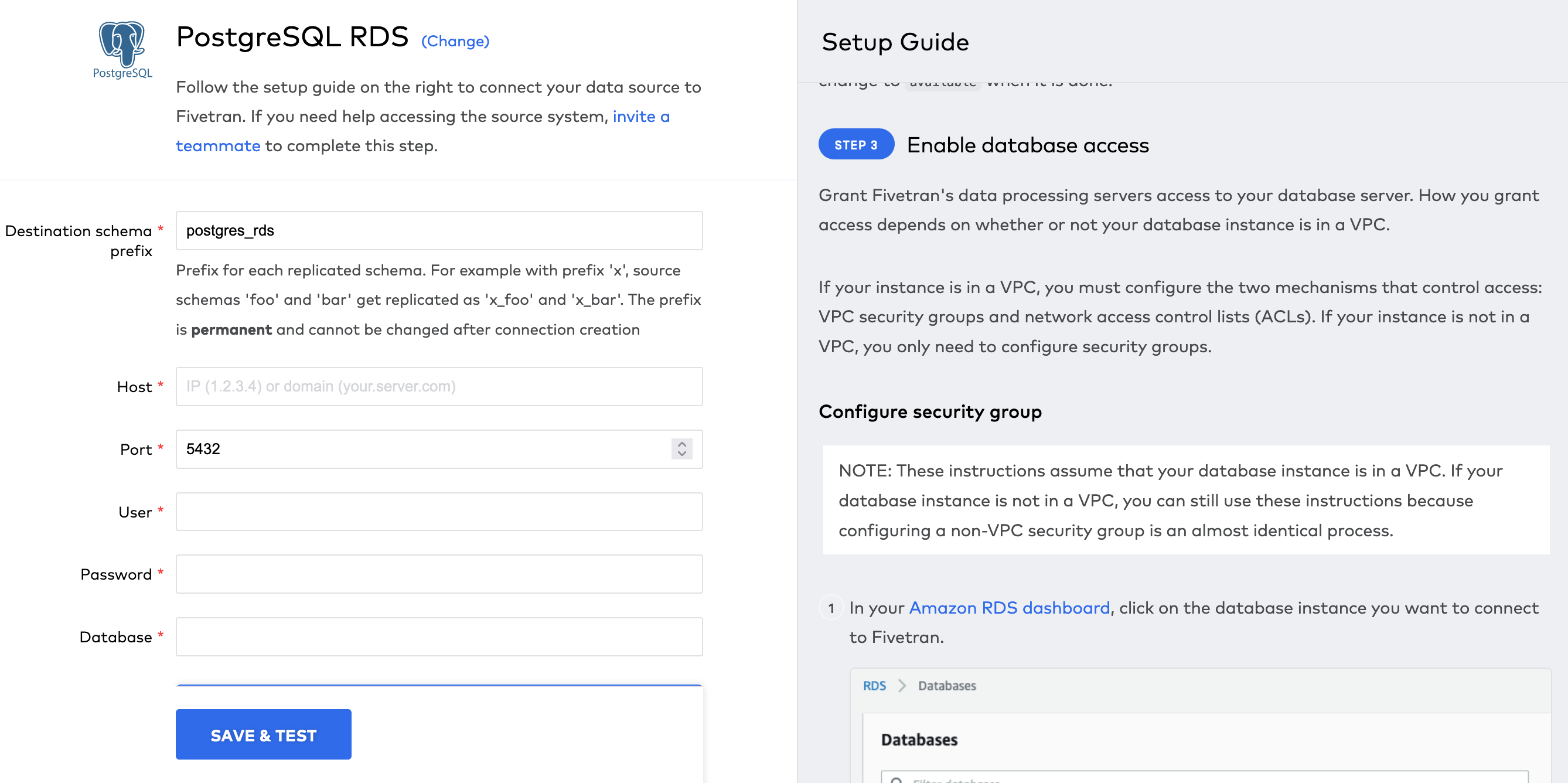
Below is a screenshot of Fivetran’s Amazon RDS PostgreSQL setup flow. It is mostly the same as their stand-alone PostgreSQL flow, but it includes screenshots of each step that needs to be taken in the AWS UI. This is the standard that we should be aiming to achieve for our setup flows.
Why not just use Fivetran?
At Tably, we want to create an experience as reassuring as Fivetran’s import flows. We want to connect as many people to their data as possible, as seamlessly as possible, with as few surprises and as little technical jargon as possible.
We don’t just want to provide lowest-common-denominator connection to all data sources though. We want to serve the long tail of people’s data needs, but there will be some data sources that deserve special attention. When we build the most beautiful and performant tool in the world, we want to have beautiful and performant ways to connect people to their data.
This means we need to be able to develop even higher-quality connectors than Fivetran. We are best placed to do this if we control setup flows that people use to connect to their data. This will give us the freedom to switch out the implementation for our own, even after things have been set up.
Serving the long tail
If we’re not using Fivetran, what are we using?
For some services that are critical to people’s success with our platform, we have our own in-house connectors.
To serve the long tail of disparate places where people’s data lives, we are standing on the shoulders of giants, and using Airbyte . Airbyte defines a unified API for connecting to various data sources, and connectors implemented for over 500 different services . These are implemented as Docker containers, which makes them easy to sandbox. They are also open-source, which makes them easily customizable.
What should our setup flows do?
Each Airbyte connector provides us with a standardized description of the values required for setting things up. This takes the form of a JSON Schema document.
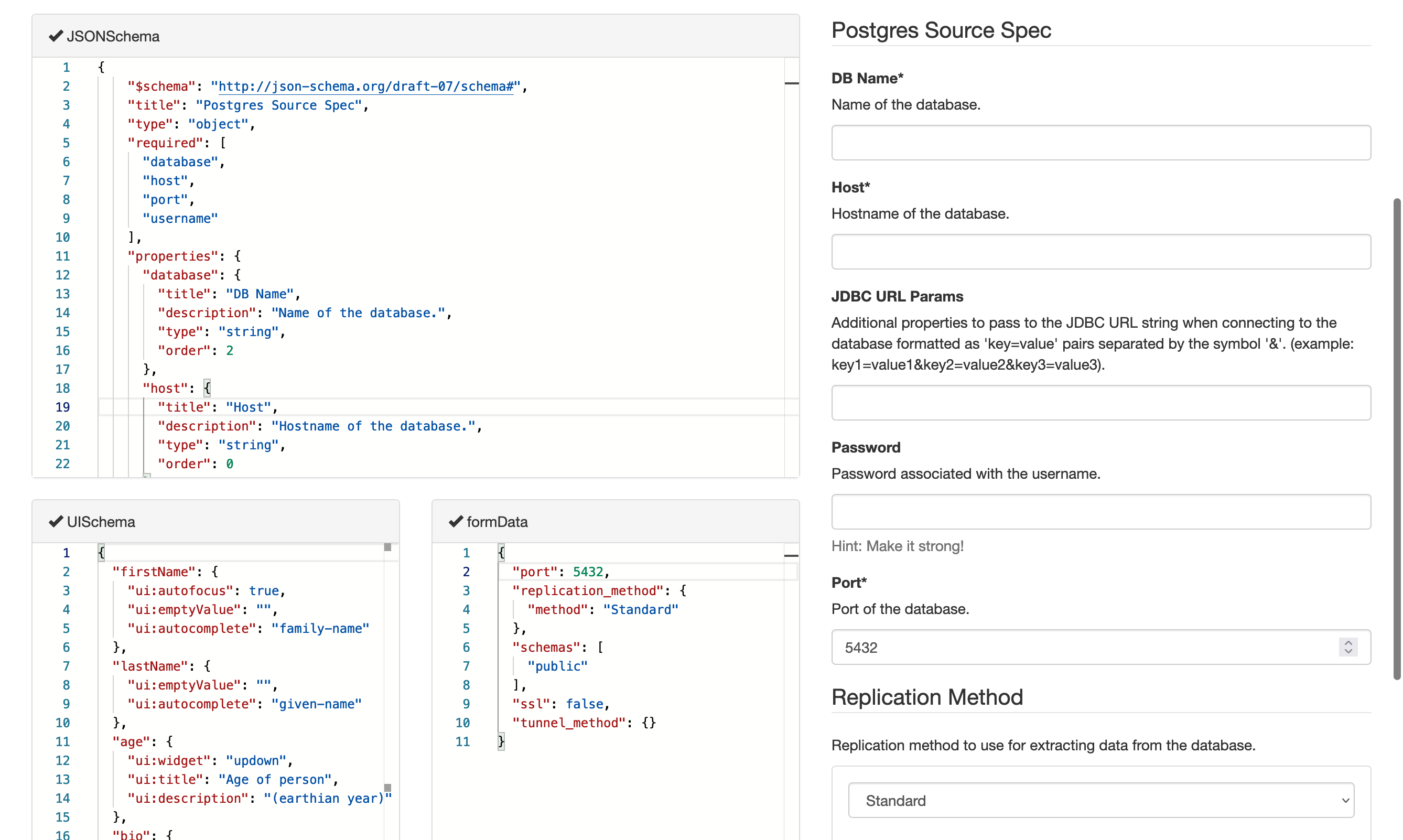
It is possible to go directly from a JSON Schema to a web form, using something like the react-jsonschema-form library. Below is a screenshot of the Airbyte PostgreSQL schema, as rendered by the react-jsonschema-form playground. It is a good first attempt, but it doesn’t understand Airbyte-specific annotations like order and airbyte_secret . It also doesn’t handle the tunnel_method field properly, because different Airbyte connectors use oneOf in multiple different ways, and the way that tunnel_method is encoded doesn’t agree with this react-jsonschema-form . Airbyte also embeds HTML inside some of its description fields, but this is not shown here.
The main problem with this form though is that it isn’t helpful . It doesn’t contain any of the richer setup instructions that Fivetran’s example does. You have to link out to the Airbyte documentation for that.
It also asks for many pieces of information that are not needed for connecting to PostgreSQL, in 80% of cases. Can we do more work behind the scenes to help out? Can we work out which fields cover 80% of people’s needs , and only ask for these things before opportunistically trying to connect to people’s data? This would let us only show the advanced options to people who need to provide them.
How do we make a flow that is even more helpful than Fivetran’s RDS flow?
Another thing to call out here is that we will be doing this for over 500 different services, and we will probably want to give helpful hints for specific situations (like how Fivetran has done for PostgreSQL). We probably don’t want to be editing “HTML inside a JSON Schema” for hundreds of forms, and we don’t want to inflict this task on technical writers either. We also probably don’t need the full expressiveness that JSON Schema gives us. We want our technical writers to be editing something that more closely maps to what people will see on tably.com.
Following the rule of least power , if we can restrict our descriptions to a format that more closely models our domain, we will be able to provide a better experience for our technical writers. Our frontend code will also be working with more constrained types, with fewer runtime edge cases.
What we want is a Domain-Specific Language.
Building our Domain-Specific Language
We started by defining a set of types that closely match the forms we want to produce. We soon had a test suite that could translate the JSON Schema from each of our Airbyte connectors into our intermediate EditableForm representation. Once we had that, we also made each EditableForm generate configurations that it thought were valid and checked them back against the JSON Schema. This gave us confidence that our types were as simple as they could be, while covering all of the cases that we were seeing in Airbyte.
In parallel with this, we worked on building out the UI components for this representation. Because the types mapped closely to our domain, we could easily maintain a 1:1 relationship between domain types and frontend components.
For our text representation, we decided to use Markdown-within-YAML as our DSL text format. It’s not perfect, but was easy to hack together quickly thanks to serde , and we know that we can switch to another format easily (by parsing our .yaml files into EditableForm type, and re-serializing them to the new format). Even if we had stuck with JSON Schema, Markdown-within-YAML is much nicer to edit than HTML-within-JSON, so this is already a win. The tooling for YAML is also pretty good. By using schemars to describe our types, we can get a lot of help from our text editor . We also made a tool that live-renders the resulting form for you, as you make edits to the text. After all of this work, the developer experience for someone who wants to improve our setup flows is pretty good.
Where are we now?
We now have the machinery in place to help people connect to their data, from over 500 different places, and we can genuinely assist them as they do so. We have Fivetran to thank for setting the bar high here, and we have Airbyte to thank for helping us reach it.
We also remain in control of the journey, so we can continue to raise the bar.
The work of writing over 500 setup guides can now start, and we have taken care to genuinely assist the people doing this work.
If you would like to try out what we’ve built, quick templates are here , or just type / on any line.
Connecting people with their data. Empathy-driven design at Tably.
By David Laban, Rust Engineer
26 Sep, 2022
User-Friendly Setup Flows
If you want people to use your tool for data work, they will need to connect your tool to their data. You can build the most beautiful and performant tool in the world, but if people can’t connect it to their data, they will not use it.
There are two extremes when it comes to connecting data tools together. On one extreme there is Singer, which takes the “configuration as code” approach, targeting the data-engineer persona.
On the other extreme, you have no-code Zapier and data warehouse-oriented Fivetran, which provide graphical setup flows for people to connect their tools together, and hold their hand throughout the process.
Below is a screenshot of Fivetran’s Amazon RDS PostgreSQL setup flow. It is mostly the same as their stand-alone PostgreSQL flow, but it includes screenshots of each step that needs to be taken in the AWS UI. This is the standard that we should be aiming to achieve for our setup flows.
Why not just use Fivetran?
At Tably, we want to create an experience as reassuring as Fivetran’s import flows. We want to connect as many people to their data as possible, as seamlessly as possible, with as few surprises and as little technical jargon as possible.
We don’t just want to provide lowest-common-denominator connection to all data sources though. We want to serve the long tail of people’s data needs, but there will be some data sources that deserve special attention. When we build the most beautiful and performant tool in the world, we want to have beautiful and performant ways to connect people to their data.
This means we need to be able to develop even higher-quality connectors than Fivetran. We are best placed to do this if we control setup flows that people use to connect to their data. This will give us the freedom to switch out the implementation for our own, even after things have been set up.
Serving the long tail
If we’re not using Fivetran, what are we using?
For some services that are critical to people’s success with our platform, we have our own in-house connectors.
To serve the long tail of disparate places where people’s data lives, we are standing on the shoulders of giants, and using Airbyte. Airbyte defines a unified API for connecting to various data sources, and connectors implemented for over 500 different services. These are implemented as Docker containers, which makes them easy to sandbox. They are also open-source, which makes them easily customizable.
What should our setup flows do?
Each Airbyte connector provides us with a standardized description of the values required for setting things up. This takes the form of a JSON Schema document.
It is possible to go directly from a JSON Schema to a web form, using something like the react-jsonschema-form library. Below is a screenshot of the Airbyte PostgreSQL schema, as rendered by the react-jsonschema-form playground. It is a good first attempt, but it doesn’t understand Airbyte-specific annotations like order and airbyte_secret. It also doesn’t handle the tunnel_method field properly, because different Airbyte connectors use oneOf in multiple different ways, and the way that tunnel_method is encoded doesn’t agree with this react-jsonschema-form. Airbyte also embeds HTML inside some of its description fields, but this is not shown here.
The main problem with this form though is that it isn’t helpful. It doesn’t contain any of the richer setup instructions that Fivetran’s example does. You have to link out to the Airbyte documentation for that.
It also asks for many pieces of information that are not needed for connecting to PostgreSQL, in 80% of cases. Can we do more work behind the scenes to help out? Can we work out which fields cover 80% of people’s needs, and only ask for these things before opportunistically trying to connect to people’s data? This would let us only show the advanced options to people who need to provide them.
How do we make a flow that is even more helpful than Fivetran’s RDS flow?
Another thing to call out here is that we will be doing this for over 500 different services, and we will probably want to give helpful hints for specific situations (like how Fivetran has done for PostgreSQL). We probably don’t want to be editing “HTML inside a JSON Schema” for hundreds of forms, and we don’t want to inflict this task on technical writers either. We also probably don’t need the full expressiveness that JSON Schema gives us. We want our technical writers to be editing something that more closely maps to what people will see on tably.com.
Following the rule of least power, if we can restrict our descriptions to a format that more closely models our domain, we will be able to provide a better experience for our technical writers. Our frontend code will also be working with more constrained types, with fewer runtime edge cases.
What we want is a Domain-Specific Language.
Building our Domain-Specific Language
We started by defining a set of types that closely match the forms we want to produce. We soon had a test suite that could translate the JSON Schema from each of our Airbyte connectors into our intermediate EditableForm representation. Once we had that, we also made each EditableForm generate configurations that it thought were valid and checked them back against the JSON Schema. This gave us confidence that our types were as simple as they could be, while covering all of the cases that we were seeing in Airbyte.
In parallel with this, we worked on building out the UI components for this representation. Because the types mapped closely to our domain, we could easily maintain a 1:1 relationship between domain types and frontend components.
For our text representation, we decided to use Markdown-within-YAML as our DSL text format. It’s not perfect, but was easy to hack together quickly thanks to serde, and we know that we can switch to another format easily (by parsing our .yaml files into EditableForm type, and re-serializing them to the new format). Even if we had stuck with JSON Schema, Markdown-within-YAML is much nicer to edit than HTML-within-JSON, so this is already a win. The tooling for YAML is also pretty good. By using schemars to describe our types, we can get a lot of help from our text editor. We also made a tool that live-renders the resulting form for you, as you make edits to the text. After all of this work, the developer experience for someone who wants to improve our setup flows is pretty good.
Where are we now?
We now have the machinery in place to help people connect to their data, from over 500 different places, and we can genuinely assist them as they do so. We have Fivetran to thank for setting the bar high here, and we have Airbyte to thank for helping us reach it.
We also remain in control of the journey, so we can continue to raise the bar.
The work of writing over 500 setup guides can now start, and we have taken care to genuinely assist the people doing this work.
If you would like to try out what we’ve built, quick templates are here, or just type / on any line.
Connecting people with their data. Empathy-driven design at Tably.

User-Friendly Setup Flows
Why not just use Fivetran?
Serving the long tail
What should our setup flows do?